Encoding reading definition: Decoding and Encoding – Scholar Within
Posted onDecoding and Encoding – Scholar Within
How are Reading and Spelling Connected?
Reading and spelling are two sides of the same coin. In order to do one part well, you need the other part.
In order to read, you need to decode (sound out) words. In order to spell, you need to encode words. In other words, to spell, you need to pull the sounds apart within a word and match the letters to the sounds.
Encoding and decoding combine the components of auditory and visual processing. Here, phonemic awareness and phonics come together in the process of reading.
This is the reason why Scholar Within’s at-home and online reading program includes spelling and phonics lessons. When you are able to spell more easily, you are also able to read more easily.
Phonemic Awareness Is Necessary for Reading and Spelling
Phoneme Blending
Phonemic awareness is your ability to manipulate the sounds in language. This is your ability to hear, identify, and manipulate individual sounds, phonemes, in spoken words. Then, you combine the phonemes to form a word. This is known as blending. You blend the individual sounds together to form a word. /c/ /a/ /t/ is cat. This is the process of decoding words.
Phoneme Segmentation
When you break a spoken word into its separate sounds, phonemes, you spell the word. This is known as encoding. This process is used when you spell a word phonetically. For example, there are five sounds in the word strip: /s/ /t/ /r/ /i/ /p/.
Combining Decoding and Encoding
So, pulling these two steps together, you are able to both sound out words, decode them, and spell them, encode them. Learning how we put letters together to make words improves your ability to read. The relationship between phonemic awareness, reading, and spelling is complementary. As you improve your spelling skills, you improve your reading skills. As you improve your reading skills by working with sound/symbol relationships, you improve your spelling skills.
Research Supports Combining Reading and Spelling
Mandi Johnson, M. Ed., author of The Relationship Between Spelling Ability and Reading Fluency and Comprehension in Elementary Students, 2013 states:
“If students have a higher knowledge of spelling, they are able to make more sense of the words that they are reading; therefore, it is easier for them to remember what is being read.”
Dr. Louisa Moats, author of How Spelling Supports Reading states:
“Spelling is a critical element not only in reading fluency and comprehension but also across the curriculum in all subject areas. It is shown that students who improve in spelling instruction, also improve in writing fluency and reading word-attack skills. If students have a higher knowledge of spelling, they are able to make more sense of the words that they are reading; therefore, it is easier for them to remember what is being read. ”
“Research shows that learning to spell and learning to read rely on much of the same underlying knowledge. Learn more about the relationships between letters and sounds and how a proper understanding of spelling mechanics can lead to improved reading.”
Learn more about the relationships between letters and sounds and how a proper understanding of spelling mechanics can lead to improved reading.”
Additionally, according to the 2007 study by Wilma Jongejan, Ludo Verhoeven, and Linda S. Siegel titled Predictors of Reading and Spelling Abilities in First-and Second-Language Learners:
“Phonological awareness was found to be of great importance for the development of literacy skills in both first and second language learners. The training of phonological awareness skills should, therefore, be encouraged for children of all linguistic backgrounds.”
Free E-book:
How to Learn to Spell
Get this e-book by joining Scholar Within’s newsletter:
Or, Sign Up Now to start your child in the spelling program.
Apply the Research
Look at the two sides of the coin: decoding and encoding. The research supports it. Reading programs should include a spelling component to help students master reading skills at a faster rate. So, we include spelling in our reading program. This solidifies the overall fluency and comprehension skills.
So, we include spelling in our reading program. This solidifies the overall fluency and comprehension skills.
At-Home Reading Program with Spelling and Phonics
Give your kids an academic advantage with our step-by-step, results-driven reading program with spelling and phonics.
In the program, your kids will learn through our custom-designed visual, auditory, and tactile methods that actually help your brain work more efficiently and make learning easier.
Reserve Your Spot
In Scholar Within’s Reading Program, your child will:
- Learn to read faster with our research-proven reading fluency drills
- Learn specific reading comprehension strategies
- Learn how to take notes easily
- Do auditory, visual, and tactile spelling lessons and activities
- Do phonemic awareness activities
- Learn phoneme segmentation through spelling lessons
- Learn to spell by spelling patterns
- Decode and encode sounds with letter combinations
- Do spelling puzzles and worksheets
- Follow along with spelling video lessons and tests
- Play card games
- And more!
Learn More
Who is Scholar Within?
Scholar Within was founded by learning expert Bonnie Terry, M. Ed., BCET. Bonnie began designing and developing her own custom educational tools when she started her private learning center in the 1990s. Teachers kept asking what she was using with the kids who saw her because of the dramatic improvements that the kids made in school. From there, Bonnie decided to make her materials available to teachers and families worldwide.
Ed., BCET. Bonnie began designing and developing her own custom educational tools when she started her private learning center in the 1990s. Teachers kept asking what she was using with the kids who saw her because of the dramatic improvements that the kids made in school. From there, Bonnie decided to make her materials available to teachers and families worldwide.
Now, Bonnie Terry has turned her materials into a full-service online program that you can follow step-by-step at home, on your schedule. School alone is not enough anymore. Bonnie’s programs boost your kid’s overall learning skills by focusing on improving the auditory, visual, and tactile processing areas of your brain to make it work more efficiently.
Learn more about Scholar Within.
What Is Encoding?: Part 1 of Encoding vs. Decoding | IMSE Journal | IMSE
“Reading and writing have been thought of as opposites – with reading regarded as receptive and writing regarded as productive. Researchers have found that reading and writing are ‘essentially the same process of meaning construction’ and that readers and writers share a surprising number of characteristics” (Carol Booth Olson, 2003).
Therefore, the explicit instruction of encoding and decoding strategies support progress toward mastery, which is the ability to read, write, and spell as one body.
Is Explicit Reading & Writing Instruction Necessary?
While oral language is a more natural human development process, written language (including reading and writing) must be taught.
Learning to read, write, and spell may be challenging for students, and seeking opportunities for incremental success through explicit, sequential, multisensory instruction proves incredibly motivating. This is especially true for English language learners and individuals with diagnosed learning disabilities such as dyslexia and dysgraphia.
IMSE Co-Founder Jeanne Jeup.
When learning something is difficult, it’s easier to dismiss it entirely. “Is this really necessary?” or “I can make it without knowing bigger words because I already know a basic word which means the same thing.”
So why is it important to continue the literacy journey? Why should I read? How will learning these [new phonetic concepts or strategies] help me in the long run? There are many reasons why reading, writing, and spelling are important.
What Is Encoding?
Spelling is critically important when completing job applications, establishing credibility as a writer, using a literal or online dictionary, or recognizing the best choice when using spell check (Liuzzo, 2020).
According to Marcia Henry (Unlocking Literacy, 2004), to be an accurate reader and speller, one must know of:
- Phonology: the study of sounds
- Orthography: the study of writing systems and sound-letter correspondences
- Morphology: the study of word parts that shape word meaning
- Etymology: the study of the history of words
According to Peter Bowers (2009), “Explicit instruction about the role of phonology and etymology is not optional if we accept the challenge of offering students accurate, comprehensive instruction.”
Encoding is the process of breaking a spoken word into each of its individual sounds, known as phonemes. Phonemes are the smallest units in our spoken language that distinguish one word from another.
Phonemes are the smallest units in our spoken language that distinguish one word from another.
“The development of automatic word recognition depends on intact, proficient phoneme awareness, knowledge of sound-symbol (phoneme-grapheme) correspondences, recognition of print patterns such as recurring letter sequences and syllable spellings, and recognition of meaningful parts of words (morphemes)” (Moats, 2020) and (Ehri, 2014).
Knowledge of spelling patterns and rules knit together the layers of the English language as students use phonology, orthography, and morphology to identify how to spell words. For example, understanding why suffix -ed makes each of its three sounds, /id/, /d/, or /t/, hinges on identifying the final sound of the base word. Students must first hear the past tense verb and isolate the base word.
In the past tense verb asked, the base word is ask which ends in unvoiced sound /k/. Therefore, in the past tense verb asked, the suffix -ed will make its unvoiced sound /t/.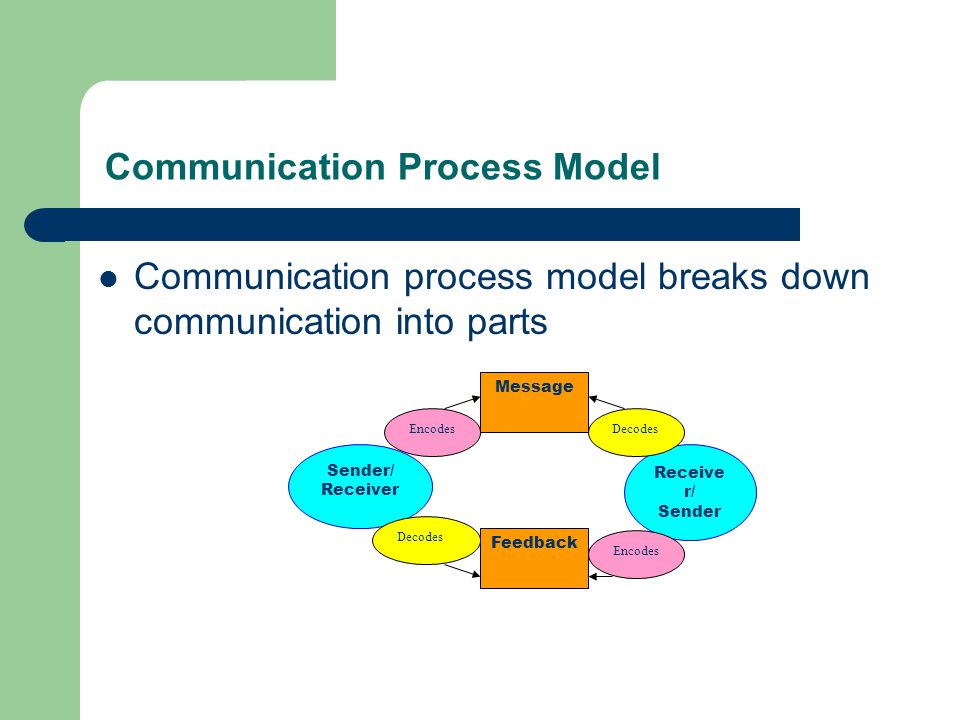 As the student encodes the word, they must apply their knowledge, as, “I hear /t/, but I write -ed.” Ensuring mastery of phonological awareness skills as a foundation upon which students build phonetic knowledge is extremely important.
As the student encodes the word, they must apply their knowledge, as, “I hear /t/, but I write -ed.” Ensuring mastery of phonological awareness skills as a foundation upon which students build phonetic knowledge is extremely important.
Students will segment to spell the phonemes in monosyllabic and polysyllabic words with increasing automaticity. Thus, a fluent writer is born.
Be sure to check out the rest of our blog series on Encoding vs. Decoding:
- Decoding Part 2 of Encoding vs. Decoding
- Irregular Words Part 3 of Encoding vs. Decoding
- What Should We Read? Part 4 of Encoding vs. Decoding
Please connect with us on Facebook, Twitter, Instagram, LinkedIn, and Pinterest to get tips and tricks from your peers and us. Read the IMSE Journal to hear success stories from other schools and districts, and be sure to check out our digital resources for refreshers and tips.
About The Author
Ginny Simank is a Level 4 IMSE OG Master Instructor living in Dallas, Texas. She has a master’s degree (M.Ed.) with a Reading Specialist certificate and holds certifications in special education, English as a Second Language, and generalists for Early Childhood through 6th grade & ELA 4th-8th grades. She is an IDA-certified Structured Literacy Teacher and full-time instructor for the Institute for Multi-Sensory Education (IMSE), whose mission is to train others across the country (teachers, administrators, tutors, education professionals & parents) in the Orton Gillingham methodology of multi-sensory language instruction. Ms. Simank previously served on the national board of directors for the Learning Disabilities Association and was a member of the LDA’s Education & Nominating Committees.
Sources
- Bowers, Peter (2009). Teaching How the Written Word Works. www.wordworkskingston.com.
- Ehri, L. “Orthographic Mapping in the Acquisition of Sight Word Reading, Spelling Memory, and Vocabulary Learning,” Scientific Studies of Reading 18 (2014): 5–21; and Kilpatrick, Essentials of Assessing.

- Ehri, L., et al., “Systematic Phonics Instruction Helps Students Learn to Read: Evidence from the National Reading Panel’s Meta-Analysis,” Review of Educational Research 71 (2001): 393–447.
- Gallagher, K. (2003). Reading Reasons: Motivational Mini-Lessons for Middle School and High School. Portland, ME: Steinhouse Publishers.
- Henry, Marcia (2004). Unlocking Literacy, Paul H. Brookes Publishing Company, Second Printing.
- Liuzzo, Jeanne (2020). Intermediate Training Manual, Institute for Multi-Sensory Education, p53-56.
- Moats, Louisa C. (2020). Teaching Reading Is Rocket Science (2020): What Expert Teachers of Reading Should Know and Be Able to Do. Washington, DC: American Federation of Teachers.
- Olson, Carol Booth. 2003. The Reading/Writing Connection: Strategies for Teaching and Learning in the Secondary Classroom. Boston: Allyn and Bacon.

Sign up for our LIVE virtual Orton-Gillingham training! We are now offering half-day, evening, and weekend options to best fit your schedule.
The IMSE approach allows teachers to incorporate the five components essential to an effective reading program into their daily lessons: phonemic awareness, phonics, vocabulary, fluency, and comprehension.
The approach is based on the Orton-Gillingham methodology and focuses on explicit, direct instruction that is sequential, structured, and multi-sensory.
It is IMSE’s mission that all children must have the ability to read to fully realize their potential. We are committed to providing teachers with the knowledge and tools to prepare future minds.
👉😊Decoding Tutoring | Brooklyn Letters😊👈
Decoding involves translating printed words to sounds or reading, and encoding is just the opposite: using individual sounds to build and write words.
In order to read and write, we must first become phonologically aware by acquiring the ability to understand that words are built from smaller sounds, or phonemes. This phonological awareness allows us to segment words into smaller sounds and, conversely, to build entire words from smaller sounds. When we learn to read, we start by making associations between each letter and its corresponding sound.
When we learn to read, we start by making associations between each letter and its corresponding sound.
In order to read and write, we must first become phonologically aware by acquiring the ability to understand that words are built from smaller sounds or phonemes. This phonological awareness allows us to segment words into smaller sounds and, conversely, to build entire words from smaller sounds. When we learn to read, we start by making associations between each letter and its corresponding sound.
To master sound-symbol association, children must understand that there is a correspondence between letters and sounds. They must understand the visual to the auditory relationship between letters and sounds (decoding/reading) as well as the auditory to a visual relationship (encoding/writing) in order to read and write efficiently.
The Five Pillars of Reading stresses the importance of phonemic awareness and phonics in building the foundations of literacy in young learners. Learn what is structured literacy.
Learn what is structured literacy.
Read about Literacy Milestones.
Phonemic Awareness
Phonemic awareness refers to the knowledge and understanding that words are built from and can be broken apart into smaller segments of a sound called phonemes. Phonemic awareness is one’s ability to hear, recognize, and manipulate sounds heard in words- think of it as the ears to brain connection.
Phonemic awareness can be taught even before a child learns to read or identify printed letters. When babies are born, they are processing phonemes when parents speak and sing to their bundle of joy. In the English language, phonemic awareness means being able to identify its approximately 44 phonemes. Additionally, teaching letter sounds with letter names is an effective way for students to grasp the concept of phonemes.
Phonics
Whereas phonemic awareness refers to one’s ability to recognize sounds or phonemes in words, phonics mastery means understanding that letters (graphemes or printed letters) of the alphabet represent sounds (phonemes)- think of it as the ears, eyes, and brain connection. A child who has mastered phonics can sound out new or unfamiliar words on their own. The child is “cracking the code” and is receiving feedback by listening to oneself sound out words.
A child who has mastered phonics can sound out new or unfamiliar words on their own. The child is “cracking the code” and is receiving feedback by listening to oneself sound out words.
Teaching phonics is all about establishing the relationship between sounds and printed letters or printed letter combinations. Starting with the printed letter-sound correspondence, a child then learns how to match sounds to letters and uses this relationship to understand printed words.
Importance of Symbol Imagery in Reading and Spelling
Sensory-cognitive skills such as phonemic awareness and symbol imagery are key in developing a child’s reading and spelling skills. Phonemic awareness refers to one’s ability to process sounds in a word, which helps a child read and spell by sounding out. However, the English language is not always phonetic, which is why many children have difficulties recognizing sight words and words that are not spelled according to their letter sounds. That is where symbol imagery comes in.
Symbol imagery involves both phonological and orthographic processing or the visual patterns of words. It refers to an individual’s ability to visualize letters and identify word patterns with their mind’s eye, allowing them to instantly recognize sight words because they have developed an extensive knowledge of them. This is crucial as reading fluency relies primarily on mastery of sight words and contextual information.
Students with strong symbol imagery show no difficulties even when encountering new or unfamiliar words, can recognize letters or common words quickly, and can self-correct their errors. At Brooklyn Letters, symbol imagery is one of the functions that we want to help strengthen in your child in order for them to become fluent readers and skilled spellers.
At Brooklyn Letters, our reading specialists provide Orton-Gillingham and Wilson tutoring services to help your child master the underlying principles of phonological awareness and symbol imagery that they need in order to become skilled readers. We offer doorstep or at-home and online tutoring. Click here to get to know our literacy specialists and find out more about reading fluency tutoring services.
We offer doorstep or at-home and online tutoring. Click here to get to know our literacy specialists and find out more about reading fluency tutoring services.
Get Started
FREE ORTON GILLINGHAM PROGRAM
Coding for Dummies, Part 1 / Sudo Null IT News
Not being an expert in the designated area, however, I read a lot of specialized literature to get acquainted with the subject and, breaking through the thorns to the stars, filled, at the initial stages, a lot of cones. With all the abundance of information, I could not find simple articles about coding as such, outside the framework of specialized literature (so to speak, without formulas and with pictures).
The article, in the first part, is an educational program on coding as such with examples of manipulations with bit codes, and in the second part I would like to touch on the simplest ways of encoding images.
0. Beginning
Since I am addressing newcomers to this issue, I do not consider it shameful to turn to Wikipedia. And there, to denote the encoding of information, we have such a definition — the process of converting a signal from a form convenient for direct use of information into a form convenient for transmission, storage or automatic processing.
And there, to denote the encoding of information, we have such a definition — the process of converting a signal from a form convenient for direct use of information into a form convenient for transmission, storage or automatic processing.
What I lacked in the 70s and 80s was at school, if not in computer science, but, for example, in mathematics lessons — basic information on coding. The fact is that each of us is engaged in coding information every second, constantly and in general — without concentrating on the coding itself. I mean, we do it all the time. So how does it happen?
Facial expressions, gestures, speech, signals of different levels — a sign with an inscription, a sign on the road, traffic lights, and for the modern world — bar codes, URLs, hash tags.
Let’s look at some in more detail.
1.1 Speech, facial expressions, gestures
Surprisingly, all these are codes. With the help of them, we transmit information about our actions, sensations, emotions. The most important thing is that the codes are understandable to everyone. For example, having been born in the dense forests of the Amazon and not seeing a modern urban person, one may encounter the problem of misunderstanding the code — a smile, like a demonstration of teeth, will be perceived as a threat, and not as an expression of joy.
The most important thing is that the codes are understandable to everyone. For example, having been born in the dense forests of the Amazon and not seeing a modern urban person, one may encounter the problem of misunderstanding the code — a smile, like a demonstration of teeth, will be perceived as a threat, and not as an expression of joy.
By definition, what happens when we talk? Thought — as a form convenient for direct use, is converted into speech — a form convenient for transmission. And, look, since sound has a limitation in both speed and transmission range, then, for example, a gesture, in some situation, can be chosen to transmit the same information, but at a greater distance.
But we will still be limited by the range of our visual acuity, and then — a person begins to invent other ways of transmitting and transforming information, for example, fire or smoke.
1.2 Interleaved signals
An Indian pings
In its primitive form, coding with interleaved signals has been used by mankind for a very long time. In the previous section, we talked about smoke and fire. If an obstacle is placed and removed between the observer and the source of fire, then the observer will think that he sees alternating «on / off» signals. By changing the frequency of such inclusions, we can develop a sequence of codes that will be unambiguously interpreted by the receiving party.
In the previous section, we talked about smoke and fire. If an obstacle is placed and removed between the observer and the source of fire, then the observer will think that he sees alternating «on / off» signals. By changing the frequency of such inclusions, we can develop a sequence of codes that will be unambiguously interpreted by the receiving party.
Along with the signal flags on sea and river vessels, the advent of radio began to use Morse code. And with all the apparent binarity (representation of the code by two values), since the dot and dash signals are used, in fact this is a ternary code, since a pause in the transmission of the code is required to separate individual character codes. That is, the Morse code, in addition to «dot-dash», which gives us the letter «A», can also sound like this — «dot-pause-dash» and then these are already two letters «ET».
1.3 Context
When we use a computer, we understand that information can be different — sound, video, text. But what are the main differences? And before you start encoding information, in order, for example, to transmit it through communication channels, you need to understand what information is in each case, that is, pay attention to the content. Sound is a series of discrete values about a sound signal, video is a series of image frames, text is a series of text symbols. If we do not take into account the context, and, for example, we use Morse code to transmit all three types of information, then if this method may be acceptable for text, then for sound and video, the time spent on transmitting, for example, 1 second of information may turn out to be too much long — an hour or even a couple of weeks.
But what are the main differences? And before you start encoding information, in order, for example, to transmit it through communication channels, you need to understand what information is in each case, that is, pay attention to the content. Sound is a series of discrete values about a sound signal, video is a series of image frames, text is a series of text symbols. If we do not take into account the context, and, for example, we use Morse code to transmit all three types of information, then if this method may be acceptable for text, then for sound and video, the time spent on transmitting, for example, 1 second of information may turn out to be too much long — an hour or even a couple of weeks.
2. Text encoding
Let’s move on from the general description of encoding to the practical part. From the conventions, we will take as a constant that we will encode data for a personal computer, where bits and bytes are taken as a unit of information. A bit is like an atom of information, and a byte is like a conditional block of 8 bits.
The text in the computer is part of 256 characters, one byte is allocated for each, and values from 0 to 255 can be used as a code. Since the data in the PC is represented in the binary number system, one byte (in the value of zero) is equal to the entry 00000000 , and 255 as 11111111. Reading such a number representation occurs from right to left, that is, one will be written as 00000001.
So, English alphabet characters 26 for upper case and 26 for lower case, 10 digits. There are also punctuation marks and other symbols, but for experiments we will use only uppercase letters and a space.
Test phrase «THE GREEK DRIVED THROUGH THE RIVER SEEES A GREEK IN THE RIVER RAK PUSHED THE GREEK’S HAND INTO THE RIVER RAK FOR THE HAND OF THE GREEK TsAP».
2.1 Block coding
Information in the PC is already represented in blocks of 8 bits, but we, knowing the context, will try to represent it in smaller blocks. To do this, we need to collect information about the characters represented and, for the future, we will immediately calculate the frequency of use of each character:
А
8
Г
4
В
3
Ч
2
Л
2
and
2
2
Д
1
Х
1
С
1
Т
1
Ц
1
H
1
1
We used 19 characters in total (including space). 18+12+11+11+9+8+4+3+2+2+2+2+1+1+1+1+1+1+1=91 bytes (91* 8=728 bits).
18+12+11+11+9+8+4+3+2+2+2+2+1+1+1+1+1+1+1=91 bytes (91* 8=728 bits).
We take these values as constants and try to change the approach to block storage. To do this, we notice that out of 256 codes for characters, we use only 19. To find out how many bits are needed to store 19 values, we must calculate LOG 2 (19) = 4.25, since we cannot use a fractional bit value, then we have to round up to 5, which gives us a maximum of 32 different values (if we wanted to use 4 bits, this would only give 16 values and we would not be able to encode the entire string).
It is easy to calculate that we get 91 * 5 = 455 bits, that is, knowing the context and changing the storage method, we were able to reduce PC memory usage by 37.5%.
Unfortunately, such a representation of information will not allow it to be unambiguously decoded without storing information about symbols and new codes, and adding a new dictionary will increase the data size. Therefore, such encoding methods manifest themselves on larger amounts of data.
In addition, to store 19 values, we used the number of bits as for 32 values, this reduces the encoding efficiency.
2.2 Variable length codes
Let’s use the same string and table and try to encode the data differently. Let’s remove the fixed size blocks and present the data based on their frequency of use — the more often the data is used, the fewer bits we will use. We get the second table:
|
Symbol |
Number |
Variable code bit |
18 |
0 |
|---|---|---|---|---|
|
Р |
12 |
1 |
||
|
К |
11 |
00 |
||
|
E |
11 |
01 |
||
|
U |
10 |
|||
|
А |
8 |
11 |
||
|
Г |
4 |
000 |
||
|
В |
3 |
001 |
||
|
h |
2 |
010 |
||
|
L |
2 |
9000 011 | ||
|
И |
2 |
100 |
||
|
З |
2 |
101 |
||
|
Д |
1 |
110 |
||
|
x |
1 |
111 |
||
|
with |
1 |
9000 0000 | ||
|
Т |
1 |
0001 |
||
|
Ц |
1 |
0010 |
||
|
Н |
1 |
0011 |
||
|
P |
1 |
0100 |
To calculate the length of the encoded message, we must add up all works of the number of characters for the length of the codes in the bit and then we get 179bit.
But this method, although it allowed to decently save memory, will not work, because it is impossible to decode it. We will not be able to determine in such a situation what the code «111» means, it can be «PPP», «RA», «AP» or «X».
2.3 Prefix block codes
To solve the problem of the previous example, we need to use prefix codes — this is a code that, when read, can be unambiguously decoded into the desired character, since only it has it. Remember earlier we talked about Morse code and there the prefix was a pause. And now we need to put into circulation some code that will determine the beginning and / or end of a specific code value.
We will compose the third table for the same line:
|
Symbol |
Number |
Prefix code with variables, bit |
0 000 |
|
|---|---|---|---|---|
|
R |
001 |
|||
|
К |
11 |
0 010 |
||
|
Е |
11 |
0 011 |
||
|
У |
9 |
0 100 |
||
|
A |
8 |
0 101 |
||
| 9000 g |
4 |
0 110 |
||
|
В |
3 |
0 111 |
||
|
Ч |
2 |
1 0001 |
||
|
l |
2 |
1 0010 |
||
|
and |
9000 2 |
1 0011 |
||
|
З |
2 |
1 0100 |
||
|
Д |
1 |
1 0101 |
||
|
x |
1 |
1 0110 |
||
|
with |
1 |
1 0111 |
||
|
Т |
1 |
1 1000 |
||
|
Ц |
1 |
1 1001 |
||
|
Н |
1 |
1 1010 | ||
|
P |
1 |
1 1011 |
The peculiarity of the new codes is that we use the first bit to indicate the size of the block following it, where 0 is a block of three bits, 1 is a block of four bits. It is easy to calculate that this approach will encode our string in 379 bits. Previously, with block coding, we got a result of 455 bits.
It is easy to calculate that this approach will encode our string in 379 bits. Previously, with block coding, we got a result of 455 bits.
We can expand this approach and increase the prefix to 2 bits, which will allow us to create 4 groups of blocks:0003
01 01
У
9
01 10
А
8
01 11
g
4
10 000 9000
9000 9000
057 10
001
Ч
2
10 010
Л
2
10 011
And
2
10 100
K
10 101
Д
1
10 110
Х
1
10 111
С
1
11 000
T
1
Ц
1
11 010
Н
1
11 011
П
1
11 100
Where 00 is a block of 1 bit, 01 is of 2 bits, 10 and 11 are of 3 bits. We calculate the size of the string — 356 bits.
We calculate the size of the string — 356 bits.
As a result, for three modifications of one method, we regularly reduce the size of the string, from 455 to 379and then up to 356 bits.
2.4 Huffman code
One of the most popular ways to construct prefix codes. Under certain conditions, it allows you to get the optimal code for any data, although it allows free modifications to the methods for creating codes.
This code ensures that there is only one unique sequence of bit values for each character. In this case, short codes will be assigned to frequent characters.
|
Symbol 011 | ||
|---|---|---|
|
У |
9 |
010 |
|
А |
8 |
1111 |
|
Г |
4 |
11011 |
|
in |
3 |
11001 |
|
h |
2 |
111011 |
|
Л |
2 |
111010 |
|
И |
2 |
111001 |
|
З |
2 |
111000 |
|
D |
1 |
1101011 |
| 9000 x |
1 |
1101010 |
|
С |
1 |
1101001 |
|
Т |
1 |
1101000 |
|
Ц |
1 |
1100011 |
|
H |
1 |
110001000 |
|
P |
1 |
110000 |
We consider the result — 328 bits.
Note that although we started using codes in 6 and 7 bits, there are too few of them to affect the outcome.
2.5.1 Strings and substrings
So far, we have encoded data as a collection of individual characters. Now we will try to encode whole words.
Let me remind you of our line: «THE GREEK RODE THROUGH THE RIVER SEE A GREEK IN THE RAK RIVER THE GREEK PUSHED HIS HAND INTO THE RAK RIVER BY THE HAND OF THE GREEK TsAP».
2
РУКУ
2
ВИДИТ
1
ГРЕКУ
1
ЕХАЛ
1
for
1
River
put
1
CAP
1
through
1
for coding. we assign an index to each word, ignore spaces and do not encode, but we consider that each word is separated by a space character.
we assign an index to each word, ignore spaces and do not encode, but we consider that each word is separated by a space character.
First we form a dictionary:
|
3 |
||
|
РУКУ |
2 |
4 |
|
ВИДИТ |
1 |
5 |
|
ГРЕКУ |
1 |
6 |
|
Dry |
1 |
7,0003 |
|
for |
1 |
8 |
|
РЕЧКЕ |
1 |
9 |
|
СУНУЛ |
1 |
10 |
|
ЦАП |
1 |
11 |
|
Chi |
1 |
Thus our line is encoded to the sequence of:
7, 0, 12, 3, 5, 0, 1, 9, 2, 10, 0, 4, 1, 3, 2, 8, 4, 6, 11
, how exactly we should encode the dictionary and data after preparatory coding is a creative process. For now, we will stay within the framework of the methods already known to us and start with block coding.
For now, we will stay within the framework of the methods already known to us and start with block coding.
Indexes are written in the form of blocks of 4 bits each (this is how indexes can be represented from 0 to 15), we will have two such chains, one for the encoded message, and the second to match the index and the word. We will encode the words themselves with Huffman codes, only we still have to set the record separator in the dictionary, you can, for example, specify the length of the word in a block, the longest word we have is 5 characters, 3 bits are enough for this, but we can also use the space code, which consists of two bits — so let’s do it. As a result, we get the dictionary storage scheme:
|
index / bit |
Word / bit |
The end of the word / bits |
|||
|---|---|---|---|---|---|
|
0/4 |
Greek / 2 9000 |
||||
|
1/4 |
iv / 5 |
Probel / 2 |
|||
|
2/4 |
Cancer / 10 |
gam0003 |
|||
|
3/4 |
River / 12 |
Probel / 2 |
|||
|
4/4 |
9000 |
PAREN |
5/4 |
sees / 31 |
Probel / 2 |
|
6/4 |
Greek / 17 |
gam0061 | |||
|
7/4 |
Heded / 20 |
Probel / 2 |
|||
| 8/4 |
9000 Bel 9/4 |
River / 18 |
Probel / 2 |
||
|
10/4 |
SUN / 26 |
Probels / 2 917 11/4 |
DAC / 17 |
Probel / 2 |
|
|
12/4 |
through / 21 |
gaps / 2 |
9 |
7 |
0 |
12 |
5 |
0 |
1 |
9000 9000 |
2 |
10 |
0 |
4 |
1 |
3 |
2 |
8 |
4 |
6 |
11 |
and the message itself, 4 bits per code.
We count everything together and get 371 bits. At the same time, the message itself was encoded in 19 * 4 = 76 bits. But we still need to keep the Huffman code and symbol matching, as in all previous cases.
Afterword
I hope the article will give a general impression of coding and show that this is not only a military cipher or a complex algorithm for mathematical geniuses.
From time to time I come across how students try to solve coding problems and simply cannot abstract, approach this process creatively. But coding is like a hairstyle or fashionable pants, which in this way show our social code.
UPD:
Since the editor of Habr destroyed the second part written, and the administration did not respond to my appeal, the continuation (written back in January) will most likely never see the light of day (two weeks of continuous work). I have no incentives to write again, count tables, write software for verification and screenshots, just as I have no desire to write something on a resource where those who disagree with the «party line» receive negative karma.
Text encoding selection when opening and saving files
As a rule, when working with text files, there is no need to delve into the technical aspects of text storage. However, if you want to share a file with a person who works with texts in other languages, download a text file from the Internet, or open it on a computer with a different operating system, you may need to set the encoding when you open or save it.
When you open a text file in Microsoft Word or another program (for example, on a computer whose operating system language is different from that in which the text in the file is written), the encoding helps the program determine how the text should be displayed on the screen in order to it could be read.
In this article
-
General information about text encoding
-
Selecting an encoding when opening a file
-
Choosing an encoding when saving a file
-
Finding encodings available in Word
Understanding text encoding
What is displayed as text on the screen is actually stored in a text file as a numeric value.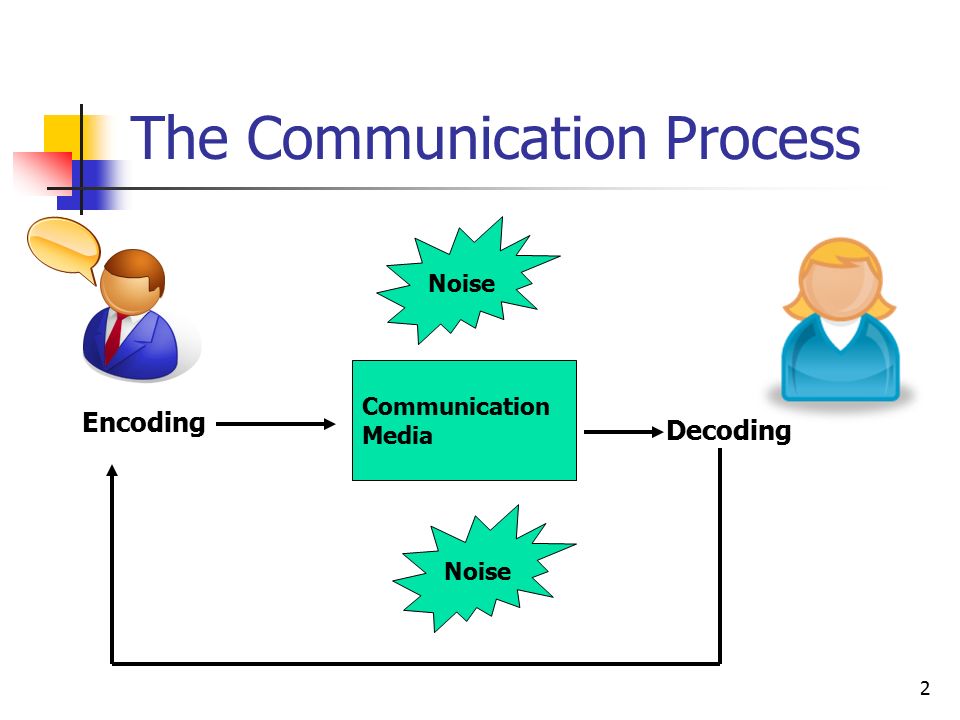 The computer converts the numerical values into visible characters. For this, a codicon is used.
The computer converts the numerical values into visible characters. For this, a codicon is used.
An encoding is a numbering scheme, according to which each text character in a set corresponds to a specific numeric value. The encoding can contain letters, numbers, and other characters. Different languages often use different character sets, so many of the existing encodings are designed to represent the character sets of their respective languages.
Different encodings for different alphabets
Encoding information saved with a text file is used by the computer to display text on the screen. For example, in the «Cyrillic (Windows)» encoding, the character «Й» corresponds to the numerical value 201. When you open a file containing this character on a computer that uses the «Cyrillic (Windows)» encoding, the computer reads the number 201 and displays «Y» sign.
However, if the same file is opened on a computer that uses a different encoding by default, the character corresponding to the number 201 in this encoding will be displayed on the screen. For example, if the encoding used on the computer is «Western European (Windows)», the «Y» character from the Cyrillic-based source text file will be displayed as «É», because this character corresponds to the number 201 in this encoding.
For example, if the encoding used on the computer is «Western European (Windows)», the «Y» character from the Cyrillic-based source text file will be displayed as «É», because this character corresponds to the number 201 in this encoding.
Unicode: a single encoding for different alphabets
To avoid problems with encoding and decoding text files, you can save them in Unicode. This encoding includes most of the characters from all languages that are commonly used on modern computers.
Since Word uses Unicode, all files in it are automatically saved in this encoding. Unicode files can be opened on any computer with an English operating system, regardless of the language of the text. In addition, Unicode files containing characters not found in Western European alphabets (such as Greek, Cyrillic, Arabic, or Japanese) can be stored on such a computer.
Top of page
Encoding selection when opening a file
If text is garbled or appears as question marks or squares in an open file, Word may have detected the encoding incorrectly. You can specify the encoding to be used to display (decode) the text.
You can specify the encoding to be used to display (decode) the text.
-
Open tab File .
-
Press button Parameters .
-
Press button Optional .
-
Go to section General and check Confirm file format conversion on open .
Note: If this check box is selected, Word displays the File Conversion dialog box every time you open a file that is not in the Word format (that is, a file that does not have a .
doc, .dot, .docx, .docm, .dotx, or .dotm extension) . If you often work with such files, but you usually do not need to choose an encoding, be sure to disable this option so that this dialog box does not appear. -
Close and then reopen the file.
-
In the File Conversion dialog box, select Encoded Text .
-
In the File Conversion dialog box, select the Other radio button and select the required encoding from the list.
In area Sample , you can view the text and check if it is displayed correctly in the selected encoding.
 doc, .dot, .docx, .docm, .dotx, or .dotm extension) . If you often work with such files, but you usually do not need to choose an encoding, be sure to disable this option so that this dialog box does not appear.
doc, .dot, .docx, .docm, .dotx, or .dotm extension) . If you often work with such files, but you usually do not need to choose an encoding, be sure to disable this option so that this dialog box does not appear. If most of the text looks the same (like squares or dots), your computer may not have the correct font installed. In this case, you can install additional fonts.
In this case, you can install additional fonts.
To install additional fonts, do the following:
-
Click the Start button and select Control Panel .
-
Do one of the following:
In Windows 7
-
On the control panel, select the section Uninstall a program .
-
In the list of programs, click Microsoft Office or Microsoft Word if it was installed separately from Microsoft Office and click the 9 button2251 Change .
On Windows Vista
-
On the control panel, select the section Uninstall a program .
-
In the list of programs, click Microsoft Office or Microsoft Word if it was installed separately from Microsoft Office and click the 9 button2251 Change .
In Windows XP
-
In Control Panel, click Add or Remove Programs .
-
In the Installed Programs list, click Microsoft Office or Microsoft Word if it was installed separately from Microsoft Office, and then click Change .
-
-
In the group Change installation of Microsoft Office , click Add or remove features , and then click Continue .
-
Under Installation Options, expand Office Common Tools and then Multilingual Support .
-
Select the desired font, click the arrow next to it, and select Run from my computer .



Tip: Word uses the fonts defined in the Web Document Options dialog box when opening a text file in a given encoding. (To display the Web Document Options dialog, press Microsoft Office Button , then click Word Options and select the category Advanced . In the General section, click the Web Document Options button.) You can use the options on the Fonts tab of the Web Document Options dialog box to configure the font for each encoding.
Top of page
Encoding selection when saving a file
If you do not select an encoding when saving the file, Unicode will be used. As a general rule, Unicode is recommended because it supports most characters in most languages.
If you plan to open the document in a program that does not support Unicode, you can select the desired encoding. For example, on an English operating system, you can create a Traditional Chinese document using Unicode. However, if such a document will be opened in a program that supports Chinese but does not support Unicode, the file can be saved in the «Chinese Traditional (Big5)» encoding. As a result, the text will display correctly when the document is opened in a program that supports Traditional Chinese.
For example, on an English operating system, you can create a Traditional Chinese document using Unicode. However, if such a document will be opened in a program that supports Chinese but does not support Unicode, the file can be saved in the «Chinese Traditional (Big5)» encoding. As a result, the text will display correctly when the document is opened in a program that supports Traditional Chinese.
Note: Since Unicode is the most complete standard, some characters may not be displayed when saving text in other encodings. Suppose, for example, that a Unicode document contains both Hebrew and Cyrillic text. If you save the file in «Cyrillic (Windows)» encoding, Hebrew text will not be displayed, and if you save it in «Hebrew (Windows)» encoding, Cyrillic text will not be displayed.
If you select an encoding standard that does not support certain characters in the file, Word marks them in red. You can preview the text in the selected encoding before saving the file.
Saving a file as encoded text removes text for which the Symbol font is selected, as well as field codes.
Encoding selection
-
Open tab File .
-
Select item Save as .
To save the file in another folder, find and open it.
-
In field File name , enter a name for the new file.
-
In the File type field, select Plain text .
-
Press button Save .
-
If the Microsoft Office Word — Compatibility Check dialog box appears, click Continue .
-
In the File Conversion dialog, select the appropriate encoding.
-
To use standard encoding, select Windows option (default) .
-
To use MS-DOS encoding, select option MS-DOS .
-
To specify another encoding, set the radio button Other and select the desired item in the list. In the area Sample , you can view the text and check if it is displayed correctly in the selected encoding.
Note: You can resize the File Conversion dialog box to increase the document display area.
-
-
If you see the message «The text highlighted in red cannot be stored correctly in the selected encoding», you can choose another encoding or check the box Allow character substitution .
If character substitution is enabled, characters that cannot be displayed will be replaced with the nearest equivalent characters in the selected encoding.
For example, the ellipsis is replaced by three dots, and the corner quotes are replaced by straight ones. If the selected encoding does not have equivalent characters for characters highlighted in red, they will be stored as out-of-context (for example, as question marks).
-
If the document will be opened in a program that does not wrap text from one line to another, you can enable hard line breaks in the document. To do this, check the box Insert line breaks and specify the desired break designation (carriage return (CR), line feed (LF) or both) in the field End lines .


 For example, the ellipsis is replaced by three dots, and the corner quotes are replaced by straight ones.
For example, the ellipsis is replaced by three dots, and the corner quotes are replaced by straight ones. Top of page
Search for encodings available in Word
Word recognizes several encodings and supports encodings that are included with the system software.
Below is a list of scripts and related encodings (code pages).
|
Writing System |
Codings |
Font used |
|---|---|---|
|
Multilingual |
Unicode (UCS-2 big endian, big endian, UTF-8, UTF-7) |
Standard font for the «Normal» style of the localized version of Word |
|
Arabic |
Windows 1256, ASMO 708 |
Courier New |
|
Chinese (simplified) |
GB2312, GBK, EUC-CN, ISO-2022-CN, HZ |
SimSun |
|
Chinese (Traditional) |
BIG5, EUC-TW, ISO-2022-TW |
MingLiU |
|
Cyrillic |
Windows 1251, KOI8-R, KOI8-RU, ISO8859-5, DOS 866 |
Courier New |
|
English, Western European and other Latin-based |
Windows 1250, 1252-1254, 1257, ISO8859-x |
Courier New |
|
Greek |
Windows 1253 |
Courier New |
|
Hebrew |
Windows 1255 |
Courier New |
|
Japanese |
Shift-JIS, ISO-2022-JP (JIS), EUC-JP |
MS Mincho |
|
Korean |
Wansung, Johab, ISO-2022-KR, EUC-KR |
Malgun Gothic |
|
Thai |
Windows 874 |
Tahoma |
|
Vietnamese |
Windows 1258 |
Courier New |
|
Indian: Tamil |
ISCII 57004 |
Latha |
|
Indian: Nepalese |
ISCII 57002 (Devanagari) |
Mangal |
|
Indian: Konkani |
ISCII 57002 (Devanagari) |
Mangal |
|
Indian: Hindi |
ISCII 57002 (Devanagari) |
Mangal |
|
Indian: Assamese |
ISCII 57006 |
|
|
Indian: Bengali |
ISC II 57003 |
|
|
Indian: Gujarati |
ISCII 57010 |
|
|
Indian: Kannada |
ISCII 57008 |
|
|
Indian: Malayalam |
ISCII 57009 |
|
|
Indian: oriya |
ISCII 57007 |
|
|
Indian: Marathi |
ISCII 57002 (Devanagari) |
|
|
Indian: Punjabi |
ISCII 57011 |
|
|
Indian: Sanskrit |
ISCII 57002 (Devanagari) |
|
|
Indian: Telugu |
ISCII 57005 |
-
Only limited support is available for Nepalese, Assamese, Bengali, Gujarati, Malayalam and Oriya.
 org/ListItem»>
org/ListItem»>
Indic languages require operating system support and appropriate OpenType fonts to be used.
Top of page
|
Main page CATEGORIES: Archeology TOP 10 on the site Preparation of disinfectant solutions of various concentrations Technique of the lower direct ball delivery. Franco-Prussian War (causes and consequences) Organization of work of the treatment room Semantic and mechanical memorization, their place and role in the assimilation of knowledge Communication barriers and ways to overcome them Processing of reusable medical devices Samples of journalistic style text Four types of rebalancing Problems with answers for the All-Russian Olympiad in Law
We will help you write your papers! DID YOU KNOW? The influence of society on a person Preparation of disinfectant solutions of various concentrations Practical work in geography for grade 6 Organization of work of the treatment room Changes in inanimate nature in autumn Treatment room cleaning Solfeggio. All rules for solfeggio Beam systems. |
⇐ PreviousPage 2 of 8Next ⇒ From the point of view of information encoding / decoding mechanisms, speech activity includes four main aspects, which are commonly called types of speech activity: speaking, listening, writing, reading. Speaking is the sending of speech acoustic signals that carry information. Listening (or listening) is the perception of speech acoustic signals and their understanding. Letter — encoding of speech signals using graphic symbols. Reading — deciphering graphic signs and understanding their meanings. Mechanisms for encoding information operate when speaking and writing, decoding mechanisms — when listening and reading. These four types of speech activity form the basis of the process of speech communication. The effectiveness of speech communication depends on the extent to which a person has formed the skills of these types of speech activity. In the process of communication, the ability to read quickly and rationally is one of the necessary conditions for effectiveness. Reading skills need to be developed by any person, as this will help to process more information and save time. To do this, you should first familiarize yourself with the essence of the reading process and master the basic techniques of reading technique.
Reading is a receptive type of speech activity associated with visual perception of a speech message encoded with graphic symbols, i.e. letters. The essence of the reading process is to decode (decode) graphic symbols and translate them into mental images. Accordingly, the reading process consists of two main stages: — stages of visual perception, — stages of comprehension (interpretation) of what has been read. At the stage of visual perception, an important role is played by the «technical skills» of reading, which can be characterized by the following indicators: — visual acuity; — the speed and nature of the movement of the eyes in the text; — field of view size, i.e. a section of text that is clearly perceived by the eyes with one fixation of the gaze. At the stage of comprehension (interpretation) of what is read, there is an understanding of the meaning of individual words, sentences, the entire text. At the second stage, “intellectual skills” of reading are important: the ability to highlight the main and basic information, the ability to memorize, the ability to concentrate, etc. Let’s consider the features of reading that hinder effective and quick comprehension of what is read. Regressions, i.e. unjustified, rote returns to what has already been read are the most common shortcomings of traditional reading. Almost all people read any text twice, regardless of its complexity. Articulation, i.e. internal pronunciation of a readable text is inherent in very many. It is formed in childhood, when the child learns to read. Gradually, a strong reflex connection is established between the read and spoken word and a habit is formed to pronounce the text, first aloud, then in a whisper, and then to oneself. Small field of view . In traditional reading, when one or two words are perceived in one fixation of the gaze, the eyes have to make many stops. The wider the field of view, the more information is perceived at each stop of the eyes, the fewer these stops, so the reading process is more efficient. A person trained in the technique of reading can perceive not two or three words, but the entire line, and sometimes even a paragraph, in one fixation of the gaze. Weak development of the semantic forecasting mechanism . Low level of attention organization . Attention is called the catalyst of the reading process. The reading speed of most readers is far below what they could have without compromising comprehension if they could control their attention. No flexible reading strategy . Usually, when people start reading, they do not set themselves any goal, they do not use the rules of text processing. Therefore, many, having read a book, an article, do not remember their title, the author, they cannot single out the main ideas of the author, concisely state the content of what they read. Ways of reading. Before you start reading, you must select a specific mode in which you will read. This mode depends on the material to be read and on the purpose of reading. It is recommended to classify texts intended for reading, depending on the purpose of reading. In its most general form, such a classification looks like this:0003 1) texts to be studied in detail; 2) texts to be read; 3) texts from which certain information must be selected. There are the following main ways of reading. I. Deep reading . With this reading, it is necessary to understand what problem the author is solving, what his point of view and conclusions are. To do this, it is necessary to comprehend the structure of the text, to compare the conclusions of the author with his own reasoning. At the same time, attention is drawn to the details of the text, their analysis and evaluation are carried out. As a result, the text must be fully assimilated, all information must be processed. 1) the main idea of the author; 2) the questions that he considers to prove his idea, the arguments that he gives; 3) the main conclusions of the author. 2. Introductory reading . The purpose of this method of reading is a general acquaintance with the content of the text. At the same time, attention is paid not to the analysis of the text, but to its informative side — as a rule, only basic information. Introductory reading is used when reading journalistic style texts (newspaper and magazine articles), and sometimes fiction. 3. Selective reading. It is not necessary to analyze all the facts contained in the text — it is enough to understand what is new, important and useful for you in such a text. 4.Read-View . One of the varieties of selective reading is reading-browsing, which is used to preview the book. 5. Scanning. This is another kind of selective reading. Scanning is a quick review of printed text in order to search for a surname, word, facts, etc. In this case, the eyes move, as a rule, in a vertical direction along the center of the page, and the vision works selectively: the reader has the intention to find only the data of interest to him. In order to master this way of reading, it is necessary to develop reading techniques, in particular, to expand the field of vision, train selective attention, etc. A person trained in this way of reading can absorb a text two to three times faster than a traditional reader. 6. Fast reading. This method of reading requires special training and is characterized not only by high reading speed, but also by high quality of reading assimilation. By alexxlab |

 Determination of support reactions and pinching moments
Determination of support reactions and pinching moments
 The degree of formation of skills of speech activity serves as a criterion for assessing the level of language proficiency and an indicator of the general culture of a person.
The degree of formation of skills of speech activity serves as a criterion for assessing the level of language proficiency and an indicator of the general culture of a person. 
 Traditional reading averages 10–15 regressions for every 100 words. It certainly slows down the reading process.
Traditional reading averages 10–15 regressions for every 100 words. It certainly slows down the reading process.  The ability to predict what is written and make semantic guesses is also called the phenomenon of anticipation. In the absence of such a skill, a person is forced to read the text from and to each word, syllable, letter, although sometimes when reading only the first two or three letters, the meaning of the word becomes quite clear. In the same way, combinations of words in a sentence can often be used to judge which word will be written next.
The ability to predict what is written and make semantic guesses is also called the phenomenon of anticipation. In the absence of such a skill, a person is forced to read the text from and to each word, syllable, letter, although sometimes when reading only the first two or three letters, the meaning of the word becomes quite clear. In the same way, combinations of words in a sentence can often be used to judge which word will be written next. 
 In order to understand the text deeply and in detail, it is recommended to understand:
In order to understand the text deeply and in detail, it is recommended to understand:  It lies in the fact that the table of contents of the book is read, the preface (the most important provisions of the author are selected) and the conclusion. The purpose of such reading is to determine whether this book should be bought, ordered from the library, whether it should be read, if necessary, in what way, etc.
It lies in the fact that the table of contents of the book is read, the preface (the most important provisions of the author are selected) and the conclusion. The purpose of such reading is to determine whether this book should be bought, ordered from the library, whether it should be read, if necessary, in what way, etc. 